Detect business failures in LLMs using RAGET
What are AI business failures?
Business failures in LLMs are failures that impact the business logic, accuracy, and reliability of your AI system. These include hallucinations, incorrect factual responses, inappropriate content generation, and failures to follow business rules.
Tip
Remember: Business failure testing is an ongoing process. Regularly test your agents and update your business failure test suites to stay ahead of emerging failures.
For more up-to-date business failure testing and a collaborative UI, see the Giskard Hub Business Failure Testing guide. Giskard Hub’s enterprise subscription leverages continuous monitoring of the latest LLM business failures and state-of-the-art research, while the open-source vulnerability database is based on 2023 data and is not regularly updated.
Note
Business failures are different from security failures. While security failures focus on malicious exploitation and system integrity, business failures focus on the agent’s ability to provide accurate, reliable, and appropriate responses in normal usage scenarios. If you want to detect security failures, check out the Detect security vulnerabilities in LLMs using LLM Scan.
How RAGET works
The RAG Evaluation Toolkit (RAGET) is a comprehensive testing framework designed specifically for Retrieval-Augmented Generation (RAG) systems. It helps you:
Generate comprehensive test sets from your knowledge base
Evaluate RAG performance across multiple dimensions
Detect business failures like hallucinations and factual inaccuracies
Ensure source attribution and grounding in your responses
RAGET automatically generates a list of question, reference_answer, and reference_context items from your RAG system’s knowledge base. It uses a sequence of LLM-powered steps to create realistic and diverse questions. The resulting test set can then be used to target and evaluate the following RAG components:
Generator: The LLM responsible for generating answers.
Retriever: Retrieves relevant documents from the knowledge base based on user queries.
Rewriter (optional): Rewrites user queries to improve relevance or incorporate chat history.
Router (optional): Filters or routes user queries based on detected intent.
Knowledge Base: The collection of documents used by the RAG system to generate answers.
Warning
Data Privacy Notice: LLM-assisted detectors send the following information to language model providers (e.g., OpenAI, Azure OpenAI, Ollama, Mistral):
Data provided in your knowledge base
Text generated by your agent
Model name and description
This does not apply if you select a self-hosted model.
Detecting business failures
Create a knowledge base
Before we can use RAGET, we need to create a knowledge base.
import pandas as pd
from giskard.rag import KnowledgeBase
# Load your data and initialize the KnowledgeBase
df = pd.DataFrame({
"samples": [
"Giskard is a great tool for testing and evaluating LLMs.",
"Giskard Hub offers a comprehensive suite of tools for testing and evaluating LLMs.",
"Giskard was founded in France by ex-Dataiku employees."
]
})
knowledge_base = KnowledgeBase.from_pandas(df, columns=["samples"])
Generate a test set
We can now use the knowledge base to generate a test set of question, reference_answer and reference_context.
from giskard.rag import generate_testset
testset = generate_testset(
knowledge_base,
num_questions=60,
# optionally, we'll auto detect the language if not provided
language='en',
# optionally, provide a description of the agent to help generating better questions
agent_description="A customer support agent for company X",
)
The generated test set contains several columns:
question: The generated question
reference_context: Context that can be used to answer the question
reference_answer: Expected answer (generated with LLM)
conversation_history: Conversation context (empty for simple questions)
metadata: Additional information about the question type and topic
Now we can save the QATestset to a file.
# Save the test set to a file
testset.save("my_testset.jsonl")
from giskard.rag.testset import QATestset
testset = QATestset.load("my_testset.jsonl")
Evaluate the test set
We will use the evaluate function to evaluate the test set with the results a provided by the predict_fn function.
This will return a report object that contains the evaluation results.
from giskard.rag import evaluate, QATestset
# Load the test set
testset = QATestset.load("my_testset.jsonl")
# Load the original knowledge base
knowledge_base = KnowledgeBase.from_pandas(df, columns=["samples"])
# Define a predict function
def predict_fn(question: str, history=None) -> str:
"""A function representing your RAG agent."""
# Format appropriately the history for your RAG agent
messages = history if history else []
messages.append({"role": "user", "content": question})
# Get the answer using your preferred framework
# could be langchain, llama_index, etc.
answer = get_answer_from_agent(messages)
return answer
# Run the evaluation and get a report
report = evaluate(predict_fn, testset=testset, knowledge_base=knowledge_base)
# We can easily visualize the results of the evaluation.
display(report)
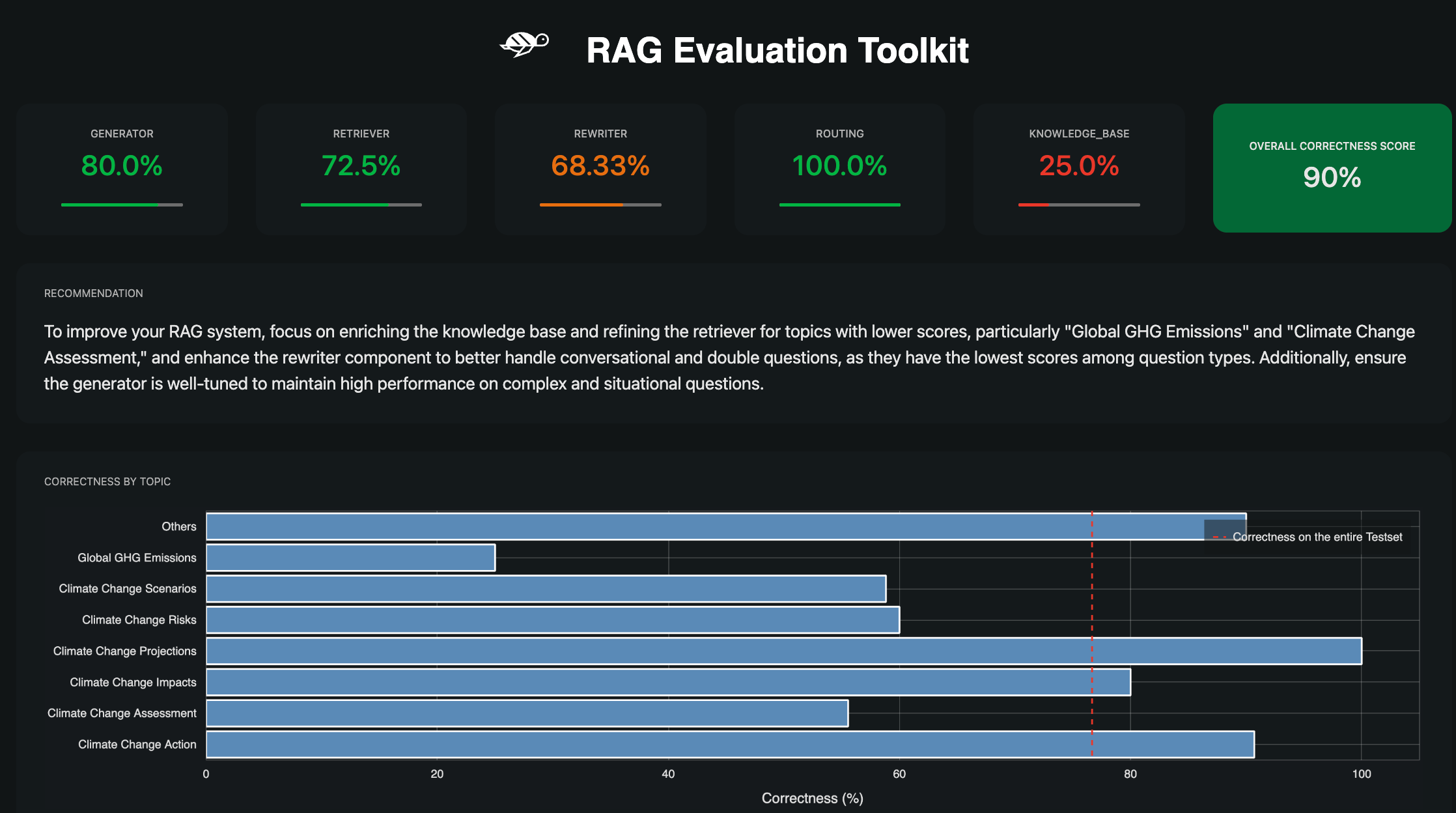
At this point, you can save and load the report. This includes the HTML report, the testset, the knowledge base, the evaluation results and the metrics if you have provided them.
report.save("path/to/my_report")
from giskard.rag.report import RAGReport
report = RAGReport.load("path/to/my_report")
Analyze Correctness and Failures
You can access the correctness of the agent aggregated in various ways or analyze only it failures.
# Correctness on each topic of the Knowledge Base
report.correctness_by_topic()
# Correctness on each type of question
report.correctness_by_question_type()
# get all the failed questions
report.failures
# get the failed questions filtered by topic and question type
report.get_failures(topic="Topic from your knowledge base", question_type="simple")
Tip
🚀 Is every single business failure too much for you?
Try our enterprise-grade solution with a free trial. Get access to advanced business logic validation, team collaboration, continuous red teaming, and more.
Request your free enterprise trial today and see the difference for yourself!
Customizing business failure testing
Custom generators
We can customize the question generation process to target and evaluate specific components in the RAG system. For example, we can generate only complex questions to evaluate the generator. And overview of the question types is available below.
Question type |
Description |
Example |
Targeted Components |
|---|---|---|---|
Simple |
Simple questions generated from an excerpt of the knowledge base |
What is the capital of France? |
Generator, Retriever, Router |
Complex |
Questions made more complex by paraphrasing |
What is the capital of the country of Victor Hugo? |
Generator |
Distracting |
Questions made to confuse the retrieval part of the RAG with a distracting element from the knowledge base but irrelevant to the question |
Italy is beautiful but what is the capital of France? |
Generator, Retriever, Rewriter |
Out of scope |
Questions that are out of scope of the knowledge base |
What are hemoglobin levels? |
Generator, Retriever, Rewriter |
Situational |
Questions including user context to evaluate the ability of the generation to produce relevant answer according to the context |
I am planning a trip to Europe, what is the capital of France? |
Generator |
Double |
Questions with two distinct parts to evaluate the capabilities of the query rewriter of the RAG |
What is the capital and the population of France? |
Generator, Rewriter |
Conversational |
Questions made as part of a conversation, first message describes the context of the question that is asked in the last message, also tests the rewriter |
Turn 1: I would like to know some information about France, Turn 2: What is its capital city? |
Rewriter |
During testset generation, you can then import and select the question types you want to use during the generation process by passing a list of question types to the question_generators parameter.
You can simply import the question generators you want to use and pass them to the question_generators parameter.
from giskard.rag import generate_testset
from giskard.rag.question_generators import (
simple_questions,
complex_questions,
conversational_questions,
distracting_questions,
situational_questions,
double_questions,
oos_questions,
)
testset = generate_testset(
knowledge_base=knowledge_base, question_generators=[
simple_questions,
complex_questions,
conversational_questions,
distracting_questions,
situational_questions,
double_questions,
oos_questions,
],
)
Alternatively, you can subclass the QuestionGenerator class and implement your own question generation logic.
You can find an example on GitHub.
from typing import Iterator
from giskard.rag.question_generators import QuestionGenerator
from giskard.rag.question_generators.prompt import QAGenerationPrompt
from giskard.rag.testset import QuestionSample
from giskard.rag.knowledge_base import KnowledgeBase
class CustomQuestionGenerator(QuestionGenerator):
_prompt = QAGenerationPrompt(
system_prompt="You are a helpful assistant.",
example_input="Where is paris located? (context: France is a country in Europe)",
example_output="{'question': 'Where is paris located?', 'answer': 'Paris is in Europe'}",
)
_question_type = "custom"
def generate_questions(
self,
knowledge_base: KnowledgeBase,
num_questions: int = 10,
agent_description: str,
language: str,
**kwargs,
) -> Iterator[dict]:
for _ in range(num_questions):
seed_document = knowledge_base.get_random_document()
context_documents = knowledge_base.get_neighbors(
seed_document, self._context_neighbors, self._context_similarity_threshold
)
context_str = "\n------\n".join(["", *[doc.content for doc in context_documents], ""])
reference_context = "\n\n".join([f"Document {doc.id}: {doc.content}" for doc in context_documents])
messages = self._prompt.to_messages(
system_prompt_input={"agent_description": agent_description, "language": language},
user_input=context_str,
)
generated_qa = self._llm_complete(messages=messages)
question_metadata = {"question_type": self._question_type, "seed_document_id": seed_document.id}
question = QuestionSample(
id=str(uuid.uuid4()),
question=generated_qa["question"],
reference_answer=generated_qa["answer"],
reference_context=reference_context,
conversation_history=[],
metadata=question_metadata,
)
yield question
my_custom_generator = CustomQuestionGenerator()
testset = generate_testset(
knowledge_base=knowledge_base,
question_generators=[my_custom_generator],
)
Custom metrics
You can also provide custom metrics to evaluate the performance of your RAG agent. By default, we always pass a correctness metric to the metrics parameter of the evaluate function.
from giskard.rag.metrics import correctness_metric
report = evaluate(predict_fn, testset=testset, knowledge_base=knowledge_base, metrics=[correctness_metric])
However, we can also use custom metrics in various ways.
You can use our built-in RAGAS metrics to evaluate the performance of your RAG agent. They directly inherit from the RAGAS library.
from giskard.rag import evaluate
from giskard.rag.metrics.ragas import (
ragas_context_precision,
ragas_faithfulness,
ragas_answer_relevancy,
ragas_context_recall,
)
report = evaluate(
predict_fn,
testset=testset,
knowledge_base=knowledge_base,
metrics=[
ragas_context_recall,
ragas_context_precision,
ragas_faithfulness,
ragas_answer_relevancy,
],
)
You can create your own custom metric by subclassing the Metric class and implementing the __call__ method.
Besides that, you need to define a clear system prompt and a user prompt that can be used by the LLM to evaluate the metric.
from giskard.llm.client import get_default_client
from giskard.llm.errors import LLMGenerationError
from giskard.rag import AgentAnswer
from giskard.rag.metrics.base import Metric
from giskard.rag.testset import QuestionSample
from giskard.rag.question_generators.utils import parse_json_output
from giskard.rag.metrics.correctness import format_conversation
from llama_index.core.base.llms.types import ChatMessage
# Ensure that the metric name is unique and used consistently
METRIC_NAME = "custom_metric"
# Define and evaluation template for the LLM
INPUT_TEMPLATE = """
Conversation: {conversation}
Reference answer: {reference_answer}
Agent answer: {answer}
Output Format (JSON only):
{{
"{metric_name}": (your rating, as a number between 1 and 5)
}}
"""
class CustomMetric(Metric):
def __call__(self, question_sample: QuestionSample, answer: AgentAnswer) -> dict:
# Implement your LLM call with litellm or any other LLM client
llm_client = self._llm_client or get_default_client()
try:
out = llm_client.complete(
messages=[
ChatMessage(
role="system",
content="You are a helpful assistant that is great at evaluating the correctness of the answer.",
),
ChatMessage(
role="user",
content=INPUT_TEMPLATE.format(
conversation=format_conversation(
question_sample.conversation_history
+ [{"role": "user", "content": question_sample.question}]
),
answer=answer.message,
reference_answer=question_sample.reference_answer,
metric_name=METRIC_NAME,
),
),
],
temperature=0,
format="json_object",
)
# We asked the LLM to output a JSON object, so we must parse the output into a dict
json_output = parse_json_output(
out.content,
llm_client=llm_client,
keys=["custom_metric"],
caller_id=self.__class__.__name__,
)
return json_output
except Exception as err:
raise LLMGenerationError("Error while evaluating the agent") from err
# Create the metric
custom_metric = CustomMetric(name=METRIC_NAME)
# Evaluate the test set
report = evaluate(predict_fn, testset=testset, knowledge_base=knowledge_base, metrics=[custom_metric])
Troubleshooting business failures
Common issues and solutions:
Low relevance scores: Check your retrieval system and document chunking
High hallucination rates: Verify context retrieval and generation logic
Poor answer quality: Ensure sufficient context is provided to the generator
Next steps
If you encounter issues with business failure testing:
Join our Discord community and ask questions in the
#supportchannelReview our glossary on AI terminology to better understand the terminology used in the documentation.