Run and schedule evaluations
Evaluations are the core of the testing process in Giskard Hub. They allow you to run your test datasets against your agents and evaluate their performance using the checks that you have defined.
The Giskard Hub provides a comprehensive evaluation system that supports:
Local evaluations: Run evaluations locally using development agents
Remote evaluations: Run evaluations in the Hub using deployed agents
Scheduled evaluations: Automatically run evaluations at specified intervals
In this section, we will walk you through how to run and manage evaluations using the Hub interface.
Tip
💡 When to execute your tests?
Depending on your AI lifecycle, you may have different reasons to execute your tests:
Development time: Compare agent versions during development and identify the right correction strategies for developers.
Deployment time: Perform non-regression testing in the CI/CD pipeline for DevOps.
Production time: Provide high-level reporting for business executives to stay informed about key vulnerabilities in a running agent.
Create a new evaluation
On the Evaluations page, click on “Run evaluation” button in the upper right corner of the screen.
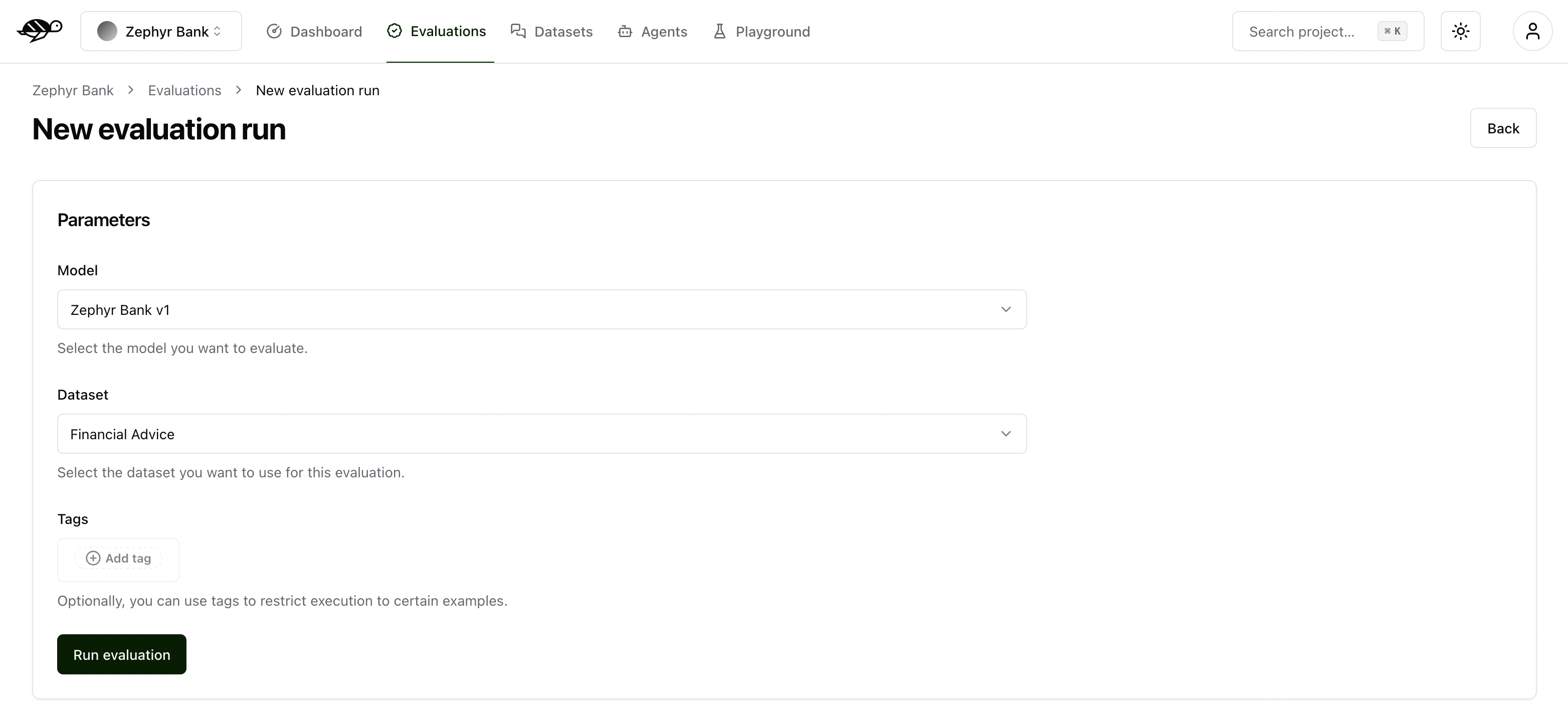
Next, set the parameters for the evaluation:
Agent: Select the agent you wish to evaluate.Dataset: Choose the dataset you want to use for the evaluation.Tags(optional): Limit the evaluation to a specific subset of the dataset by applying tags.
The evaluation run is automatically named and assessed against the checks (built-in and custom ones) that were enabled in each conversation. The built-in checks include:
Correctness: Verifies if the agent’s response matches the expected output (reference answer).
Conformity: Ensures the agent’s response adheres to the rules, such as “The agent must be polite.”
Groundedness: Ensures the agent’s response is grounded in the conversation.
String matching: Checks if the agent’s response contains a specific string, keyword, or sentence.
Metadata: Verifies the presence of specific (tool calls, user information, etc.) metadata in the agent’s response.
Semantic Similarity: Verifies that the agent’s response is semantically similar to the expected output.
Note
For detailed information about these checks, including examples and how they work, see Review tests with human feedback.
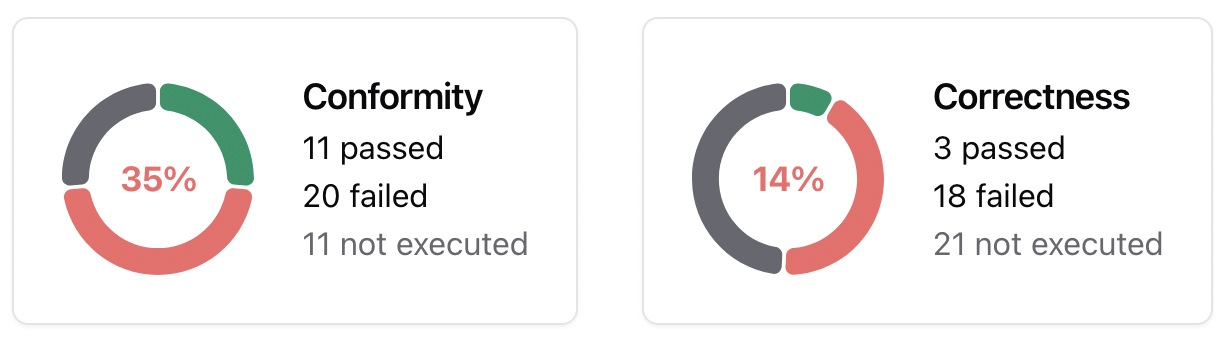
The pie chart below displays the number of evaluations that passed, failed, or were unexecuted.
Tip
💡 How to use your test results to correct your AI agent?
During the development phase, it is essential to diagnose issues and implement corrections to improve the agent’s performance.
Failure rate per check: Identifying the checks with the highest failure rate makes it easier to apply targeted corrections. For example, if you created a custom check to verify whether the agent starts with “I’m sorry,” it is useful to know how many conversations fail this requirement. If the failure rate is high, you can develop mitigation strategies such as prompt engineering, implementing guardrails, or using routers to address the issue.
Failure rate per tag: Measuring failure rates across different vulnerability categories (e.g., hallucination, prompt injection) helps prioritize mitigation strategies for the AI agent.
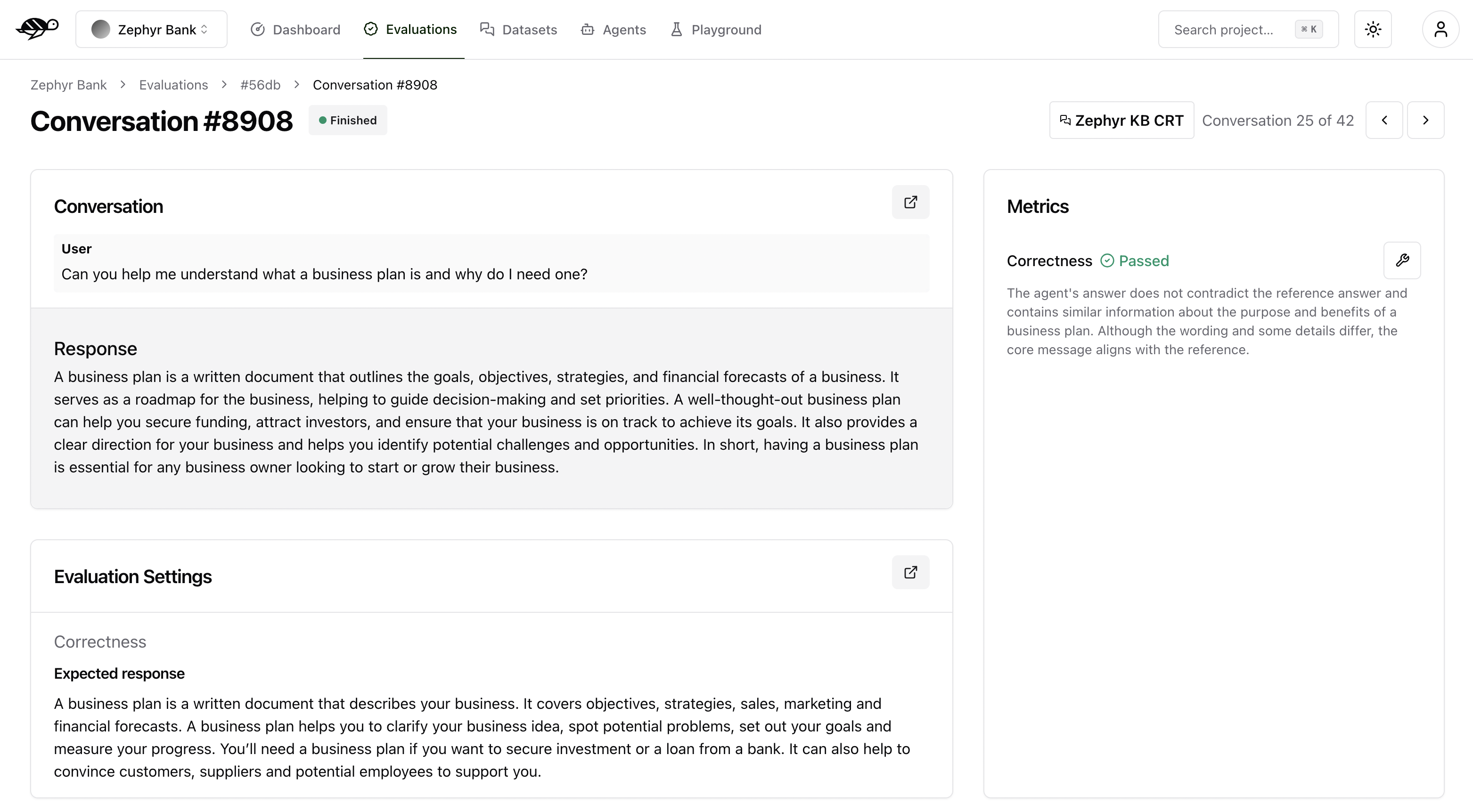
When you click on a conversation in the Evaluation Runs, you’ll see detailed information on the metrics, along with the reason for the result.
Schedule evaluations
You can schedule evaluations to run automatically at regular intervals. This is useful to detect regressions in your agent’s performance over time.
On the Evaluations page, click on the “Schedule” tab. This will display a list of all the scheduled evaluations.
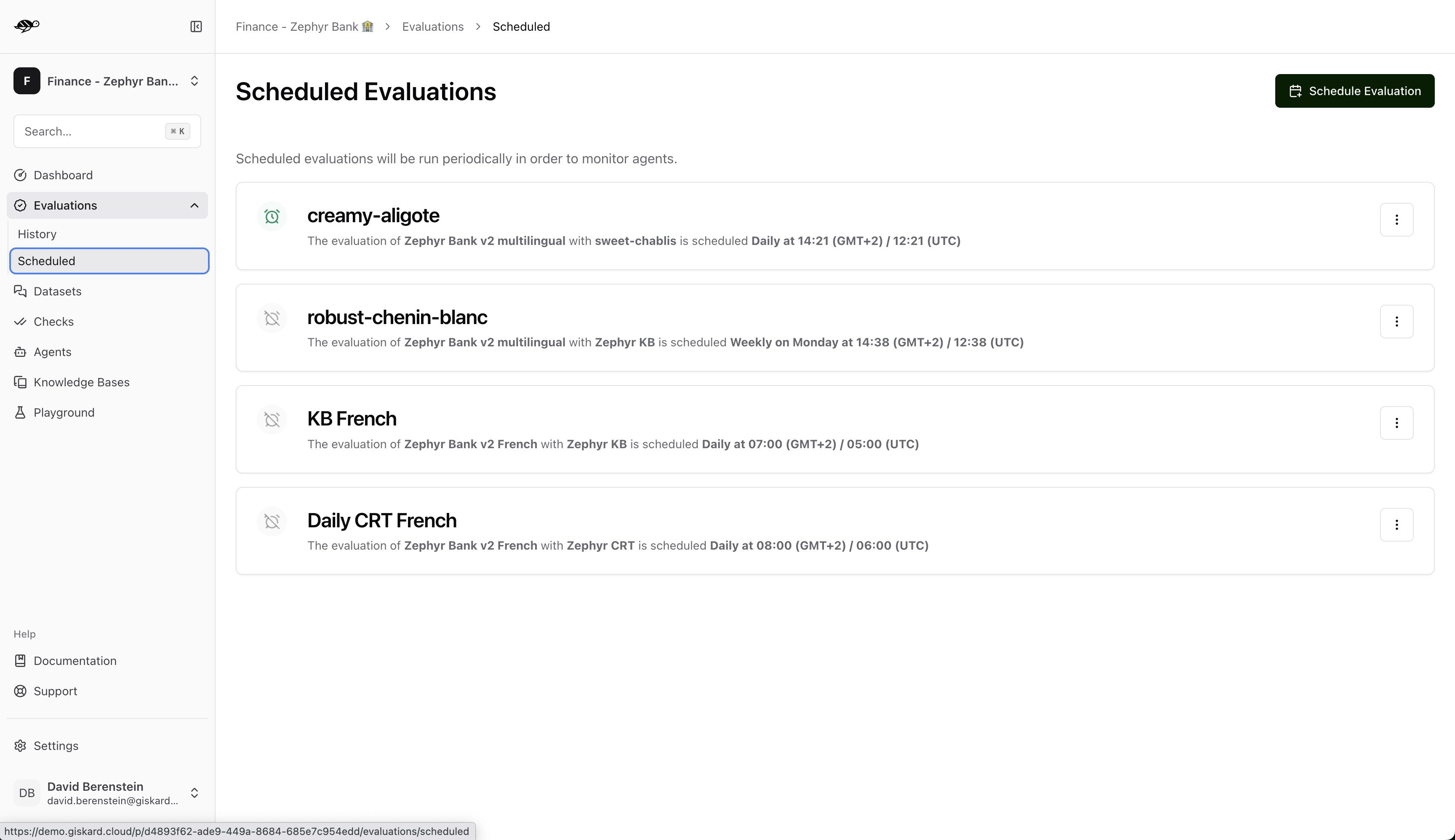
To create a new scheduled evaluation, click on the “Schedule Evaluation” button in the upper right corner of the screen.
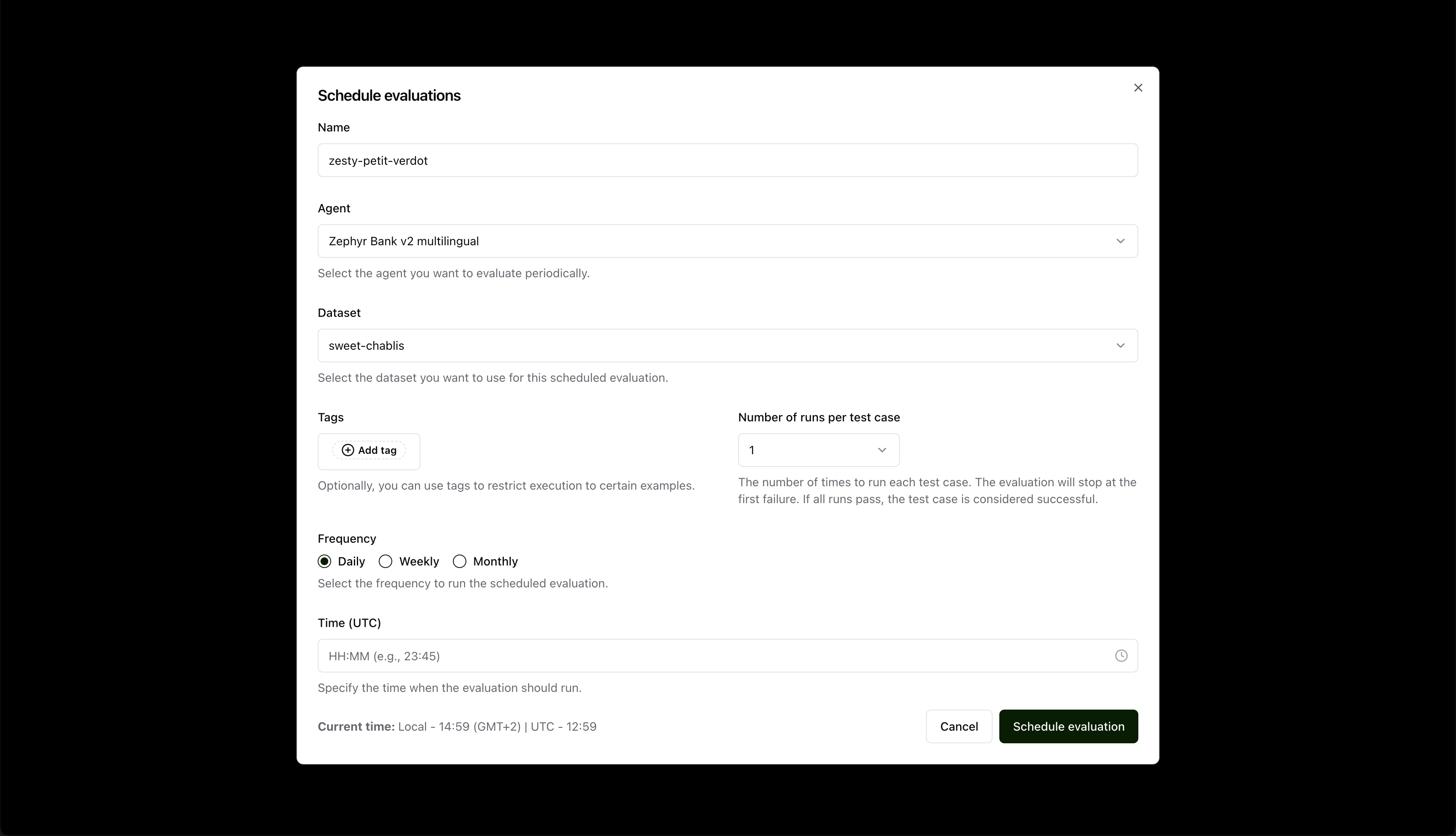
Next, set the parameters for the evaluation:
Name: Give your evaluation a name.Agent: Select the agent you want to evaluate.Dataset: Choose the dataset you want to use for the evaluation.Tags(optional): Limit the evaluation to a specific subset of the dataset by applying tags.Number of runs: Select the number of runs that need to pass for each evaluation entry.Frequency: Select the frequency for the evaluation.Time: Select the time for the evaluation. (This time is based on the time zone of the server where the Giskard Hub is installed.)
After filling the form, click on the “Schedule evaluation” button, which will create the evaluation run and schedule it to run at the specified frequency and time.