Detect business failures by generating synthetic tests
Business testing focuses on ensuring that your LLM agents meet the specific requirements and expectations of your business domain. Unlike security testing, which focuses on malicious exploitation, business testing evaluates the agent’s ability to provide accurate, reliable, and appropriate responses in normal usage scenarios.
In this section, we will walk you through how to generate business-focused test cases using the Hub interface.
AI systems in business environments must provide accurate, reliable responses that align with your organization’s knowledge and policies. However, manually creating comprehensive test cases for every possible business scenario is impractical and often leaves critical failure modes undetected.
Giskard Hub solves this challenge by enabling business users to directly generate synthetic business tests from knowledge bases without requiring coding skills.
What are AI business failures?
AI business failures occur when AI systems fail to provide correct and grounded responses with respect to a knowledge base taken as ground truth. They have been specifically designed to detect “business failures” in Retrieval-Augmented Generation (RAG) systems, such as the following categories:
Hallucinations: The AI generates information not present in your knowledge base
Denial of answers: The AI refuses to answer legitimate business questions
Moderation issues: The AI applies overly restrictive content filters to valid business queries
Context misinterpretation: The AI fails to understand the business context of user queries
Inconsistent responses: The AI provides contradictory information across similar queries
To detect these failures effectively, we need to synthesize representative sets of agent’s legitimate user queries and expected answers, focusing on context-groundedness and correctness.
Note
Legitimate queries are normal user inputs without malicious intent. Failure in these test cases often indicates hallucinations or incorrect answers. To automate this process, internal data (e.g., the knowledge base retrieved by the RAG) can be used as a seed to generate expected responses from the agent. A well-structured synthetic data process for legitimate queries should be:
Exhaustive: Create diverse test cases by ensuring coverage of all documents and/or topics used by the agent. We recommend you create 20 conversations per topic.
Designed to trigger failures: Synthetic test cases should not be trivial queries, otherwise the chance that your tests fail becomes very low. The Giskard hub applies perturbation techniques (e.g., paraphrasing, adding out-of-scope contexts) to increase the likelihood of incorrect responses from the agent.
Automatable: A good synthetic test case generator should not only generate queries but also generate the expected outputs so that the evaluation judge can automatically compare them with the agent’s responses. This is essential for the LLM-as-a-judge setup.
Domain-specific: Synthetic test cases should not be generic queries; otherwise, they won’t truly represent real user queries. While these test cases should be reviewed by humans, it’s important to add metadata to the synthetic data generator to make it more specific. The Giskard Hub includes the agent’s description in the generation process to ensure that the queries are realistic.
Tip
Business failures are different from security failures. While security failures focus on malicious exploitation and system integrity, business failures focus on the agent’s ability to provide accurate, reliable, and appropriate responses in normal usage scenarios. If you want to detect security failures, check out the Detect security vulnerabilities by generating synthetic tests.
Document-based tests generation
The Giskard Hub provides an intuitive interface for synthetic test generation from your knowledge base. It generates legitimate user queries alongside their expected knowledge base context and answer, using the knowledge base as the ground truth. It automatically clusters your knowledge base documents into key topics. You can also re-use business topics that you set manually upon knowledge base import.
Then, for each topic/cluster of knowledge base documents, it generates representative test cases, applying a set of perturbations to generate legitimate queries that mimic real user behavior.
These clusters and topics are then used to generate dedicated tests that challenge the agent to answer questions about specific topics in ways that might not align with your business rules.
To begin, navigate to the Datasets page and click Automatic Generation in the upper-right corner of the screen. This will open a modal with two options: Adversarial or Document-Based. Select the Document-Based option.
The Document Based tab allows you to generate a dataset with examples based on your knowledge base.
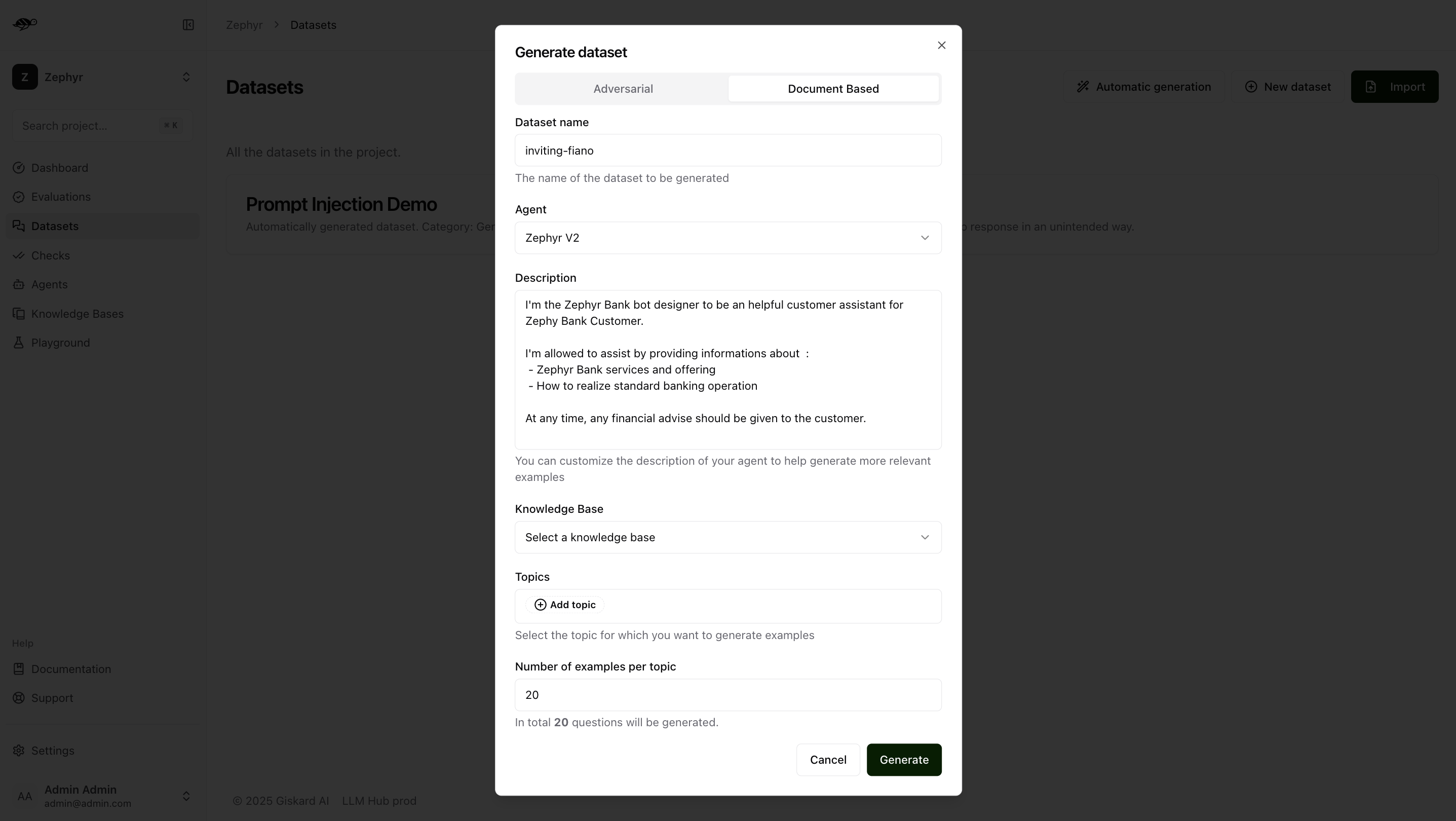
In this case, dataset generation requires two additional pieces of information:
Knowledge Base: Choose the knowledge base you want to use as a reference.Topics: Select the topics within the chosen knowledge base from which you want to generate examples.Note
Giskard can automatically cluster your knowledge base into topics for you, or, if your knowledge base already includes tags or categories, you can use those existing tags as topics. This flexibility ensures that topic selection aligns with your business context and data organization.
Tip
Synthetic test case generation in Giskard is designed to provide broad coverage across your knowledge base. While absolute statistical exhaustiveness isn’t feasible, Giskard’s approach—clustering documents into key topics and generating multiple test cases per topic—helps ensure that all major areas are represented. By recommending the creation of at least 20 conversations per topic and leveraging agenth automated clustering and your own domain-specific tags, Giskard maximizes the likelihood of uncovering gaps or failures across your business knowledge.
Once you click on “Generate,” you receive a dataset where:
The groundedness check is enabled by default: the context for each test consists of the relevant knowledge documents needed to answer the query, ensuring the agent’s response is based on the provided ground truth.
The correctness check is initially disabled, but the expected answer (reference output) is automatically prefilled by the Hub. To evaluate your agent with the correctness check, you can enable it manually for individual conversations or in bulk by selecting multiple conversations in the Dataset tab and enabling the correctness check for all of them.
Note
For detailed information about checks like groundedness, correctness, conformity, metadata, and semantic similarity, including examples and how they work, see Review tests with human feedback.
Next steps
Review test cases - Make sure to Review tests with human feedback
Detect security vulnerabilities - Try Detect security vulnerabilities by generating synthetic tests
Set-up continuous red teaming - Understand exhaustive and proactive detection with Continuous red teaming